





Linear Regression Model
This is the type of Supervised Learning Algorithms. Here we will predict a value after getting some inputs. We have some features x (if you have multiple features then x will become x1, x2, x3 and so on)as input. We will take these features and feed them to a trained model and our model will predict a value as output. In this way linear Regression Model works. Now let’s try to go in depth of model.
If we break the model as initial stage then it will be like this
Feature (x) — — — — — — — — → Model (f(x)) — — —— — — — -> Prediction (y)
Here f(x)= w*x +b, Maybe you are thinking what is this so let me explain. Here w is some weight, x is feature and b is bias. Let’s assume you bought 3 eggs (egg is feature) and price of a egg is 10 rupees (here price is weight and bias is 0(you can also take 1 as a bias). We know that weight and bias can be high or low according to the situation) Now let’s predict the price of egg as output by putting detail in the equation which we named as model
w=10; x=3; b=0
f(x)=w* x + b — — — — — — — — — -> 10 * 3 + 0 — — — — — — — — — -> 30 (this is prediction which we can say y)
Our actual price of eggs (actual-y) is 30. This means that we have 2 y’s first one is predictive y and second one is actual y. Predictive y denotes to that price which we predict by our own with the help of our model using that information which we have. And actual y denotes the actual or real price of eggs according to the market. After comparing the actual y with predictive y if both are near to each other means about the same then our model prediction is good if they are not same or near to each other then our model prediction is not good. Like other mathematic scenarios we should have some equation to measure this error between actual-y and predictive-y and here it is, to measure this error we have a method called cost function. formula is given below.
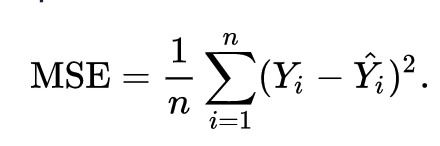
Here n is number of training examples and Y[i] is actual value and Y^ is predicted value. We will put the values inside this function if output will be close to zero then our output is accurate otherwise we have to change the parameters (weight and bias) to make prediction accurate. Now maybe you are confusing how parameters (we are using parameter word for w and b)are changing, actually for training purpose when we are trying to train the model with the help of features x then we will check the actual-y with predictive-y at every iteration every error is high then we will change the weight and bias or update the weight and bias according to the situation. There are lot of the techniques to update the weights and bias for now you have to take the overview of the concept. We will cover the complete process how model trains itself in upcoming tutorials. At this stage you should familiar with Gradient Decent technique to update the weights and bias. Formula to update weight and bias using gradient decent is given below


Example of Linear Regression using Single Neuron:

This Diagram shows the method of prediction that how model predicts the value. For today’s blog your understanding for predicting values should be clear.




